![[HR]](../../IMAGES/REDBAR.GIF)
To preserve compatibility, the $CRMPSC system service interprets the value of the relpag argument in 512-byte units on both VAX systems and Alpha systems. Note, however, that because the CPU-specific page size on Alpha systems is larger than 512 bytes, the address specified by the offset in the relpag argument probably does not fall on a CPU-specific page boundary. The $CRMPSC system service can map virtual memory in CPU-specific page increments only. Thus, on Alpha systems, the mapping of the section file will start at the beginning of the CPU-specific page that contains the offset address, not at the address specified by the offset.
Note
Even though the routine starts mapping at the beginning of the CPU-specific page that contains the address specified by the offset, the start-address returned in the retadr argument is the address specified by the offset, not the address at which mapping actually starts.
If your application maps from an offset into a section file, you may need to enlarge the size of the address range specified in the inadr argument to accommodate the extra virtual memory space that gets mapped on Alpha systems. If the address range specified is too small, your application may not map the entire portion of the section file you desire, because the mapping begins at an earlier starting address in the section file.
For example, to map 16 blocks in a section file starting at block number 15 on a VAX system, you could specify an address range 16*512 bytes in size in the inadr argument and specify a value of 15 for the relpag argument. To accomplish this same mapping on an Alpha system, you must allow for the difference in page sizes. For example, on an Alpha system with an 8KB page size, the address specified by the relpag offset might fall 15 pagelets into a CPU-specific page, as shown in Figure 5-2. Because the $CRMPSC system service on an Alpha system begins the mapping of the section file at a CPU-specific page boundary, it would fail to map blocks 16 through 30. For the mapping to succeed, you would need to increase the size of the address range to accommodate the additional 15 pagelets mapped by the $CRMPSC system service (or the $MGBLSC system service) on an Alpha system. Otherwise, only one block of the portion of the section file you specified would be mapped.
Figure 5-2 Effect of Address Range on Mapping from an Offset
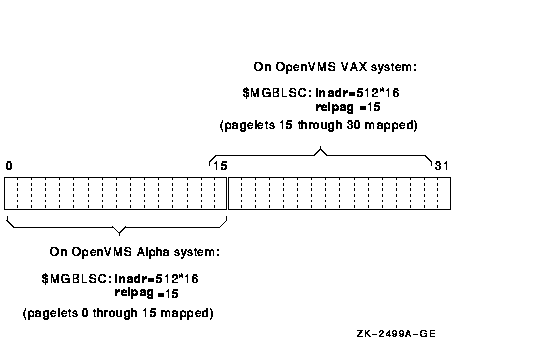
When trying to calculate how much to enlarge the size of the address
range specified in the relpag argument, the following
formula may be helpful. The formula calculates the maximum number of
CPU-specific pages needed to map a given number of pagelets.
(
number
pagelets
For example, this formula can be used to calculate how much to enlarge the address range specified in the previous scenario. In the following equation, the page size is assumed to be 8K, so pagelets_per_page equals 16:
16+((2x16)-2)/16=2.87...
Rounding the result down to the nearest whole number, the formula
indicates that the address range specified in the
inadr argument must encompass two CPU-specific pages.
5.4 Obtaining the Page Size at Run Time
To obtain the page size supported by an Alpha system, use the $GETSYI system service. Example 5-6 shows how to use this system service to obtain the page size at run time.
Example 5-6 Using the$GETSYI System Service to Obtain the CPU-Specific Page Size
#include <ssdef.h>
#include <stdio.h>
#include <stsdef.h>
#include <descrip.h>
#include <dvidef.h>
#include <rms.h>
#include <secdef.h>
#include <syidef.h> /* defines page size item code symbol */
struct itm { /* define item list */
short int buflen; /* length in bytes of return value buffer */
short int item_code; /* item code */
long bufadr; /* address of return value buffer */
long retlenadr; /* address of return value length buffer */
} itmlst[2];
long cpu_pagesize;
long cpu_pagesize_len;
main( argc, argv )
int argc;
char *argv[];
{
int status = 0;
itmlst[0].buflen = 4; /* page size requires 4 bytes */
itmlst[0].item_code = SYI$_PAGE_SIZE; /* page size item code */
itmlst[0].bufadr = &cpu_pagesize; /* address of ret_val buffer */
itmlst[0].retlenadr = &cpu_pagesize_len; /* addr of length of ret_val */
itmlst[1].buflen = 0;
itmlst[1].item_code = 0; /* Terminate item list with longword of 0 */
status = sys$getsyiw( 0, 0, 0, &itmlst, 0, 0, 0 );
if( status & STS$M_SUCCESS )
{
printf("getsyi succeeds, page size = %d\n",cpu_pagesize);
exit( status );
}
else
{
printf("getsyi fails\n");
exit( status );
}
}
The $LKWSET system service locks into the working set the range of pages identified in the inadr argument as an address range on both VAX and Alpha systems. The system service rounds the addresses to CPU-specific page boundaries if necessary.
However, because Alpha instructions cannot contain full virtual addresses, Alpha images must reference procedures and data indirectly through a pointer to a procedure descriptor. The procedure descriptor contains information about the procedure, including the actual code address. These pointers to procedure descriptors and data are collected into a new program section called a linkage section.
Recommendation
On Alpha systems, it is not sufficient to simply lock a section of code into memory to improve performance. You must also lock the associated linkage section into the working set.
To lock the linkage section in memory, determine the start- and end-addresses of the linkage section and pass these addresses as values in the inadr argument to a call to the $LKWSET system service.
This chapter describes synchronization mechanisms that ensure the
integrity of shared data, such as the atomicity guaranteed by certain
VAX instructions.
6.1 Overview
If your application uses multiple threads of execution and the threads share access to data, you may need to add explicit synchronization mechanisms to your application to protect the integrity of the shared data on Alpha systems. Without synchronization, an access to the data initiated by one application thread can potentially interfere with an access initiated simultaneously by a competing thread, leaving the data in an unpredictable state.
On VAX systems, the degree of synchronization required depends on the relationship of the different threads of execution, which can include the following:
On VAX systems, applications that take advantage of the parallel processing potential of a multiprocessor system have always had to provide explicit synchronization mechanisms such as locks, semaphores, and interlocked instructions to protect shared data. However, applications that use multiple threads on uniprocessor systems may not explicitly protect the shared data. Instead, these applications may depend on the implicit protection provided by features of the VAX architecture that guarantee synchronization between application threads executing on a VAX uniprocessor system (described in Section 6.1.1).
For example, applications that use a semaphore variable to synchronize
access to a critical region of code by multiple threads depend on the
semaphore being incremented atomically. On VAX systems, this is
guaranteed by the VAX architecture. The Alpha architecture does not
make the same synchronization guarantees. On Alpha systems, access to
this semaphore or any data that can be accessed by multiple threads of
execution must be explicitly synchronized. Section 6.1.2 describes
features of the Alpha architecture you can use to provide equivalent
protection.
6.1.1 VAX Architectural Features That Guarantee Atomicity
The following features of the VAX architecture provide synchronization among multiple threads of execution running on a uniprocessor system. (Note that the VAX architecture does not extend this guarantee of atomicity to multiprocessor systems.)
To provide compatibility with the atomicity capabilities of the VAX architecture, the Alpha architecture defines two mechanisms:
One way to uncover synchronization assumptions in your application is to identify data that is shared among multiple threads of execution and then examine each access to the data from each thread. When looking for shared data, remember to include unintentionally shared data as well as intentionally shared data. Unintentionally shared data is shared because of its proximity to data that is accessed by multiple threads of execution such as data written to by ASTs generated by the operating system as a result of system services such as $QIO, $ENQ, or $GETJPI.
Because compilers on Alpha systems use quadword instructions by default in certain circumstances, all data items within a quadword of a shared data item may potentially become unintentionally shared. For example, compilers use quadword instructions to access a data item that is not aligned on natural boundaries. (Data is naturally aligned when its address is divisible by its size. For more information, see Chapter 7. Compilers align explicitly declared data on natural boundaries by default.)
When examining data access, determine if another thread could view the data in an intermediate state and, if such a view is possible, whether it is important to the application. In some cases, the exact value of the shared data may not be important; the application depends only on the relative value of the variable. In general, ask the following questions:
Figure 6-1 shows this decision process.
Figure 6-1 Synchronization Decision Tree
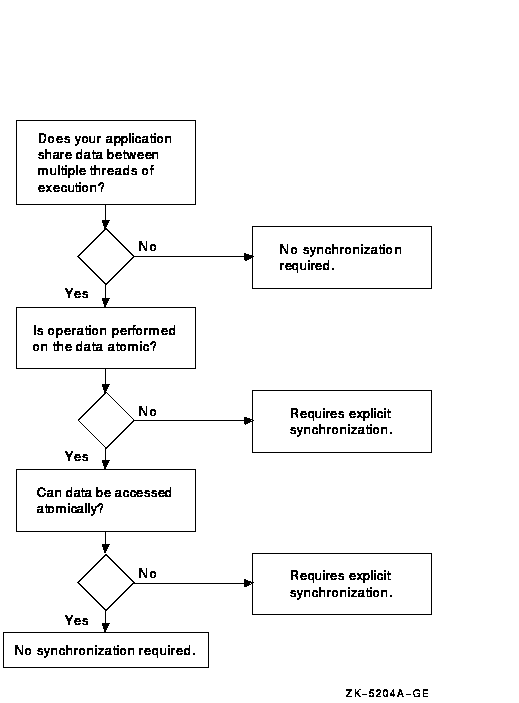
Example 6-1 is a simplified example of some possible atomicity assumptions in a VAX application. The program uses a variable, flag, through which an AST thread communicates with a main processing thread of execution. The main processing loop continues working until the counter variable reaches a predetermined value. The program queues an AST interruption that sets the flag to the maximum value, terminating the processing loop.
Example 6-1 Atomicity Assumptions in a Program with an AST Thread
#include <ssdef.h>
#include <descrip.h>
#define MAX_FLAG_VAL 1500
int ast_rout();
long time_val[2];
short int flag; /* accessed by main and AST threads */
main( )
{
int status = 0;
static $DESCRIPTOR(time_desc, "0 ::1");
/* changes ASCII time value to binary value */
status = SYS$BINTIM(&time_desc, &time_val);
if ( status != SS$_NORMAL )
{
printf("bintim failure\n");
exit( status );
}
/* Set timer, queue ast */
status = SYS$SETIMR( 0, &time_val, ast_rout, 0, 0 );
if ( status != SS$_NORMAL )
{
printf("setimr failure\n");
exit( status );
}
flag = 0; /* loop until flag = MAX_FLAG_VAL */
while( flag < MAX_FLAG_VAL )
{
printf("main thread processing (flag = %d)\n",flag);
flag++;
}
printf("Done\n");
}
ast_rout() /* sets flag to maximum value to stop processing */
{
flag = MAX_FLAG_VAL;
}
In Example 6-1, the variable named flag is explicitly shared between the main thread of execution and an AST thread. The program does not use any synchronization mechanism to protect the integrity of this variable; it implicitly depends on the atomicity of the increment operation.
On an Alpha system, this program may not always work as desired because the mainline thread of execution can be interrupted in the middle of the increment operation by the AST thread before the new value is stored back into memory, as shown in Figure 6-2. (This would be more likely to fail in a real application with dozens of AST threads.) In this scenario, the AST thread would interrupt the increment operation before it completes, setting the value of the variable to the maximum value. But once control returns to the main thread, the increment operation would complete, overwriting the value of the AST thread. When the loop test is performed, the value would not be at its maximum and the processing loop would continue. Figure 6-2 Atomicity Assumptions in Example 6-1
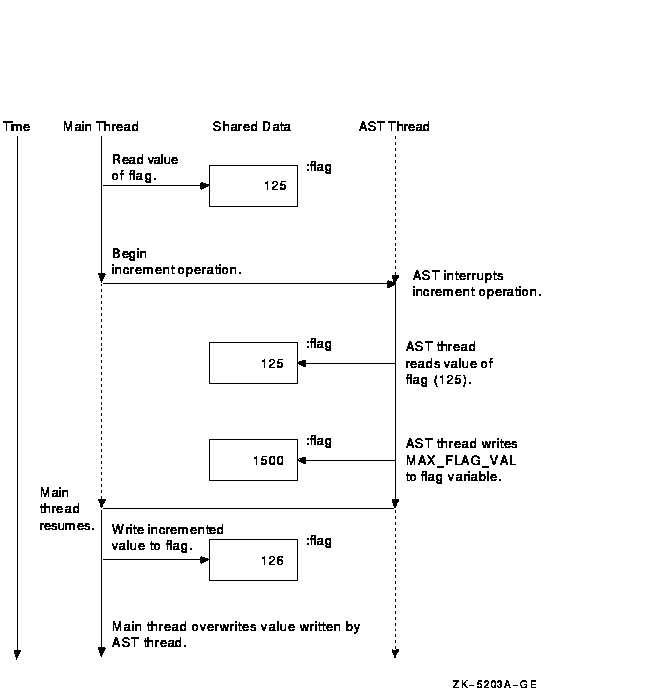
Recommendations
To correct these atomicity dependencies, Digital recommends doing the following:
Example 6-2 shows how these changes are implemented in the program presented in Example 6-1. Example 6-2 Version of Example 6-1 with Synchronization Assumptions
#include <ssdef.h>
#include <descrip.h>
#include <builtins.h> (1)
#define MAX_FLAG_VAL 1500
int ast_rout();
long time_val[2];
int (2) flag; /* accessed by mainline and AST threads */
main( )
{
int status = 0;
static $DESCRIPTOR(time_desc, "0 ::1");
/* changes ASCII time value to binary value */
status = SYS$BINTIM(&time_desc, &time_val);
if ( status != SS$_NORMAL )
{
printf("bintim failure\n");
exit( status );
}
/* Set timer, queue ast */
status = SYS$SETIMR( 0, &time_val, ast_rout, 0, 0 );
if ( status != SS$_NORMAL )
{
printf("setimr failure\n");
exit( status );
}
flag = 0;
while( flag < MAX_FLAG_VAL ) /* perform work until flag set to zero */
{
printf("mainline thread processing (flag = %d)\n",flag);
__ADD_ATOMIC_LONG(&flag,1,0); (3)
}
printf("Done\n");
}
ast_rout() /* sets flag to maximum value to stop processing */
{
flag = MAX_FLAG_VAL;
}
The items in the following list correspond to the numbers in Example 6-2:
In Example 6-1, both threads clearly access the same variable. However, on an Alpha system, it is possible for an application to have atomicity concerns for variables that are inadvertently shared. In this scenario, two variables are physically adjacent to each other within the boundaries of a longword or quadword. On VAX systems, each variable can be manipulated individually. On an Alpha system, which supports atomic read and write operations of longword and quadword data only, the entire longword must be fetched before the target bytes can be modified. (For more information about this change in data-access granularity, see Chapter 7.)
To illustrate this problem, consider a modified version of the program in Example 6-1 in which the main thread and the AST thread each increment separate counter variables that are declared in a data structure, as in the following code:
struct {
short int flag;
short int ast_flag;
};
If both the main thread and the AST thread attempt to modify their individual target words simultaneously, the results would be unpredictable, depending on the timing of the two operations.
To remedy this synchronization problem, Digital suggests doing the following:
struct {
double flag;
double ast_flag;
};
VAX multiprocessing systems have traditionally been designed so that if one processor in a multiprocessing system writes multiple pieces of data, these pieces become visible to all other processors in the same order in which they were written. For example, if CPU A writes a data buffer (represented by X in Figure 6-3) and then writes a flag (represented by Y in Figure 6-3), CPU B can determine that the data buffer has changed by examining the value of the flag.
On Alpha systems, read and write operations to memory may be reordered to benefit overall memory subsystem performance. Processes that execute on a single processor can rely on write operations from that processor becoming readable in the order in which they are issued. However, multiprocessor applications cannot rely on the order in which write operations to memory become visible throughout the system. In other words, write operations performed by CPU A may become visible to CPU B in an order different from that in which they were written.
Figure 6-3 depicts this problem. CPU A requests a write operation to X, followed by a write operation to Y. CPU B requests a read operation from Y and, seeing the new value of Y, initiates a read operation of X. If the new value of X has not yet reached memory, CPU B receives the old value. As a result, any token-passing protocol relied on by procedures running on CPUs A and B is broken. CPU A could write data and set a flag bit, but CPU B may see the flag bit set before the data is actually written and erroneously use stale memory contents.
Figure 6-3 Order of Read and Write Operations on an Alpha System
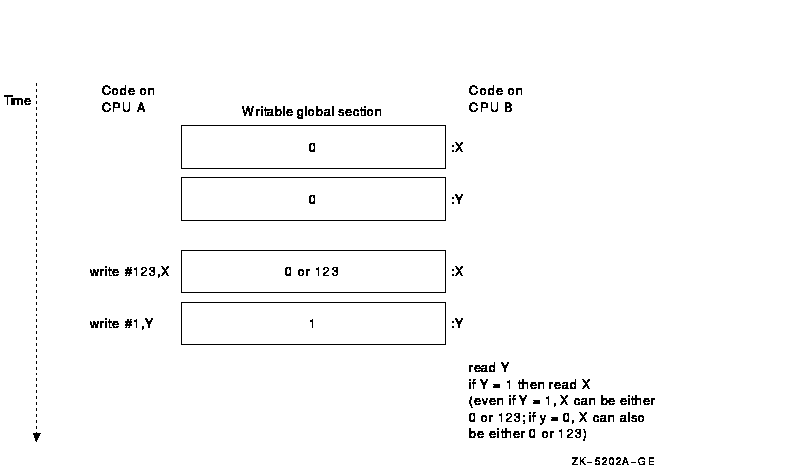
Recommendations
Programs that run in parallel and that rely on read/write ordering require some redesigning to execute correctly on an Alpha system. One or more of the following techniques may be appropriate, depending on the application:
The VEST command's /PRESERVE qualifier accepts keywords that allow translated VAX images to run on Alpha systems with the same guarantees of atomicity that are provided on VAX systems. Several /PRESERVE qualifier keywords provide different types of atomicity protection. Note that specifying these /PRESERVE qualifier keywords can have an adverse effect on the performance of your application. (For complete information about specifying the /PRESERVE qualifier, see DECmigrate for OpenVMS AXP Systems Translating Images.)
6459P007.HTM OSSG Documentation 22-NOV-1996 13:07:14.83
Copyright © Digital Equipment Corporation 1996. All Rights Reserved.