![[HR]](../../IMAGES/REDBAR.GIF)
6489P017.HTM OSSG Documentation 22-NOV-1996 13:17:00.86
Copyright © Digital Equipment Corporation 1996. All Rights Reserved.
The following two examples use the default key.
$ SORT NAMES.LST BYNAME.LST
Figure 11-1 List Sorted in Ascending Order

$ SORT NAMES.LST,NAMES2.LST BYNAME.LST
See Section 11.10 for a complete list of SORT qualifiers.
11.3.3 Defining a Key
Use the /KEY qualifier to define a key. When specifying multiple keys,
use a separate /KEY qualifier for each key.
Table 11-2 describes the five elements that comprise a key.
| Key Element | Value | Description | |||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Key position | POSITION: n | The position of the first byte of the key field within the record. The first byte in a record is position 1. POSITION: n is required. | |||||||||||||||
| Key size | SIZE: n |
The length of the key field. SIZE:
n is required except for floating point data.
The data type you specify for the key determines what values are acceptable when specifying size. The following table lists the possible values for each type of data and the units used to specify the size of the key.
For decimal data, if the decimal sign is stored in a separate byte, that byte is not counted toward the size of the data. If you specify a key that extends beyond the end of a record, Sort treats the missing characters as null characters. |
|||||||||||||||
| Data type | CHARACTER | Character data. CHARACTER is the default data type. | |||||||||||||||
| BINARY |
Binary data.
SIGNED --- Signed binary or decimal data. SIGNED is the default for binary and decimal data. UNSIGNED --- Unsigned binary or decimal data. |
||||||||||||||||
| F_FLOATING | F_FLOATING format data. | ||||||||||||||||
| D_FLOATING | D_FLOATING format data. | ||||||||||||||||
| G_FLOATING | G_FLOATING format data. | ||||||||||||||||
| H_FLOATING | On VAX systems, H_FLOATING format data. (Not currently supported by the high-performance Sort/Merge utility.) | ||||||||||||||||
| S_FLOATING | On Alpha systems, IEEE S_FLOATING format data. | ||||||||||||||||
| T_FLOATING | On Alpha systems, IEEE T_FLOATING format data. | ||||||||||||||||
| DECIMAL |
Decimal data.
TRAILING_SIGN --- Trailing sign decimal data. TRAILING_SIGN is the default for decimal data. LEADING_SIGN --- Leading sign decimal data. The leading sign must be in the first position of the field and the field must be left zero padded. OVERPUNCHED_SIGN --- Overpunched decimal data. OVERPUNCHED_SIGN is the default for decimal data. SEPARATE_SIGN --- Separate sign decimal data. |
||||||||||||||||
| ZONED | Zoned decimal data. (Not currently supported by the high-performance Sort/Merge utility.) | ||||||||||||||||
| PACKED_DECIMAL | Packed decimal data. | ||||||||||||||||
| Sort order | ASCENDING | Orders the sorting operation in ascending alphabetical or numerical order. ASCENDING is the default order. | |||||||||||||||
| DESCENDING | Orders the sorting operation in descending alphabetical or numerical order. | ||||||||||||||||
| Key priority | NUMBER: n | Specifies the order of priority of each key if you do not list multiple keys in the order of their priority. A value of 1 to 255 can be specified. | |||||||||||||||
If the data in the key fields is not character data, you must specify the data type. The following data types are recognized by the Sort/Merge utility:
| BINARY, [SIGNED] | |
| BINARY, UNSIGNED | |
| CHARACTER | |
| DECIMAL, LEADING_SIGN, SEPARATE_SIGN [SIGNED] | |
| DECIMAL, LEADING_SIGN, [OVERPUNCHED_SIGN, SIGNED] | |
| DECIMAL [,SIGNED, TRAILING_SIGN, OVERPUNCHED_SIGN] | |
| DECIMAL, [TRAILING SIGN], SEPARATE_SIGN, [SIGNED] | |
| DECIMAL, UNSIGNED | |
| D_FLOATING | |
| F_FLOATING | |
| G_FLOATING | |
| H_FLOATING | |
| S_FLOATING, IEEE (Alpha systems only) | |
| T_FLOATING, IEEE (Alpha systems only) | |
| PACKED_DECIMAL | |
| ZONED |
The items in brackets are defaults and need not be specified.
Note
For decimal string data, the Sort/Merge utility reports an invalid digit in the input string differently for VAX and Alpha systems. On VAX systems, you receive a message that the invalid digit (or reserved operand) is converted to a valid decimal string for comparison purposes. On Alpha systems, Sort/Merge performs the same conversion but does not display a message. In both cases, the data from the input file is written to the output file without change.
In Figure 11-2, each record in the file EMPLOYEE.LST consists of three fields: (1) a department name, (2) an account number, and (3) a customer name.
Figure 11-2 Record Fields in a List

The following examples illustrate how to sort the records in EMPLOYEE.LST both with, and without, a key field:
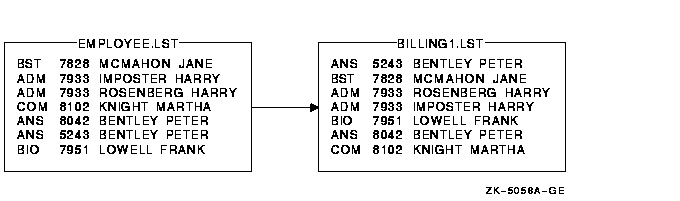
$ SORT/KEY=(POSITION:5,SIZE:4,DECIMAL) EMPLOYEE.LST BILLING1.LST
Figure 11-3 Sorting by Key Field
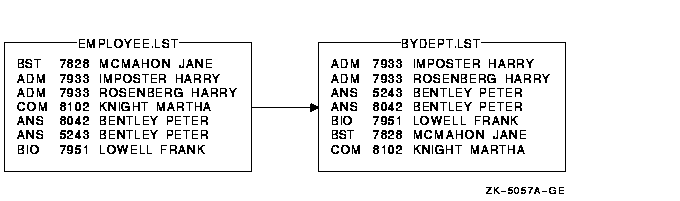
$ SORT EMPLOYEE.LST BYDEPT.LST
Figure 11-4 Sorting with Default Key Records
You can sort with more than one key (up to a limit of 255 keys). You can specify multiple keys in order of their priority with the primary key first, the secondary key next, and so on. Alternately, you can specify a key's priority using NUMBER:n. Each key can be ascending or descending.
Examples
$ SORT /KEY=(POSITION:10,SIZE:15,CHARACTER) - _$ /KEY=(POSITION:5,SIZE:4,DECIMAL) EMPLOYEE.LST BILLING2.LST
Figure 11-5 Sorting with Multiple Key Fields

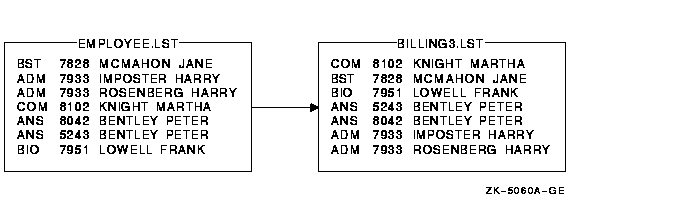
$ SORT/KEY=(POSITION:1,SIZE:3,DESCENDING) - _$ /KEY=(POSITION:10,SIZE:15) - _$ EMPLOYEE.LST BILLING3.LST
Figure 11-6 Sorting with Multiple Key Fields (Ascending and Descending Order)
By default, Sort/Merge keeps records with identical key fields but does not necessarily maintain the same order in which they appeared in the input file. To control the way in which records with identical keys are sorted, specify one of the following qualifiers:
The /STABLE and /NODUPLICATES qualifiers are incompatible. You cannot specify both qualifiers on the same command line.
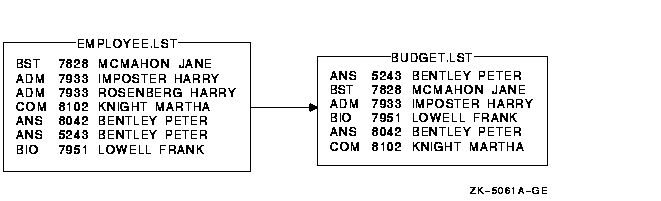
In the following example, records with duplicate account numbers are eliminated from the file EMPLOYEE.LST:
$ SORT /KEY=(POSITION:5,SIZE:4)/NODUPLICATES EMPLOYEE.LST BUDGET.LST
Figure 11-7 shows the results of this Sort operation.
Figure 11-7 Sorting with Identical Key Fields
If you sort records that contain items other than character data, specify the data type of each key. In addition, take care in calculating starting positions and sizes because the items being compared can occupy more than 1 byte.
Example
If you are sorting a file that contains 20 characters followed by 3 floating-point numbers in F_floating format, the positions are as follows:
To sort the file by the third floating-point number, specify the key field as follows:
$ SORT/KEY=(POSITION:29,F_FLOATING) STATS.RAW STATS.SOR
You do not need to specify the size of the floating-point number
because it is fixed at four bytes.
11.3.7 Output File Organization
By default, Sort produces an output file with the same file organization as that of the first input file. To specify a different output file organization, include one of the following qualifiers after the output file specification on the Sort command line:
Example
In the following example, a sequential file is produced after the indexed sequential file EMPLOYEE.LST is sorted:
$ SORT/KEY=(POSITION:10,SIZE:15) - _$ EMPLOYEE.LST BYNAME.LST/SEQUENTIAL
Sort arranges files using one of the internal processes: record, tag, address, or indexed. (The high-performance Sort/Merge utility supports only the record process. Implementation of tag, address, and index processes is deferred to a future OpenVMS Alpha release.) The process you specify can affect the efficiency of the Sort operation. Refer to Section 11.9 for information about optimizing a Sort or Merge operation.
The following table describes the four types of process. Use the /PROCESS=type qualifier to specify the sort process.
| Sort Process | type | Description |
|---|---|---|
| Record | RECORD | Keeps records intact while sorting and produces an output file consisting of complete records. Record is the default sorting process. |
| Tag | TAG |
Sorts the key fields only and then rereads the input file to produce an
output file of complete records. The net result is the same as for a
complete record sort.
A tag sort is useful if disk space is low because it typically uses less work file space during the sorting. In most cases, a tag sort is slower than a record sort because it requires extra time to reread the input file. |
| Address | ADDRESS |
Sorts the key fields only and produces an output file that is an index
of
record file addresses (RFAs) in binary format.
An address sort is faster than a record sort but you must write a program to associate the record addresses with the records of the input file. |
| Indexed | INDEX |
Sorts the key fields only and produces an output file of keys and RFAs
(in binary format).
As with an address sort, an index sort is faster than a record sort, but you must write a program to associate the record addresses with the records of the input file. |
11.4 Specifying a Collating Sequence
Characters are sorted according to a collating sequence. For
files that contain character data, you can use the
/COLLATING_SEQUENCE=sequence qualifier to specify the
collating sequence. The following table describes the collating
sequence options.
| Collating Sequence | sequence | Description |
|---|---|---|
| ASCII | ASCII | The default collating sequence for character data. The ASCII sequence orders numbers (0 to 9) first, then uppercase letters (A to Z), and then lowercase letters (a to z). |
| EBCDIC | EBCDIC | Generates an output file that is ordered in EBCDIC sequence. The data remains in the ASCII representation. The EBCDIC sequence orders lowercase letters (a to z) first, then uppercase letters (A to Z), and then numbers (0 to 9). |
| DEC Multinational character set | MULTINATIONAL |
The multinational collating sequence collates characters according to
the DEC Multinational character set (refer to Appendix B). In the
MULTINATIONAL character sequence, characters are ordered according to
the following rules:
|
| National character set (NCS) | Collating sequence name |
The named collating sequence must be defined in an NCS library. For
more information, see the OpenVMS National Character Set Utility Manual. NCS collating sequences are
supported only through the command line interface and not through
specification files.
(The high-performance Sort/Merge utility does not support the National Character Set (NCS) collating sequences. Support for NCS collating sequences is deferred to a future OpenVMS Alpha release.) |
| User-defined sequence | (sequence-string) |
Specifies a user-defined collating sequence. User-defined collating
sequences are supported only through specification files and not
through the command line interface.
(The high-performance Sort/Merge utility does not support user-defined collating sequences. Support for user-defined collating sequences is deferred to a future OpenVMS Alpha release.) |
|
Define a collating sequence by specifying a string of single or double
characters or ranges of single characters. (A double character is any
set of two single characters collated as if they were one character.
For example, "CH" can be defined to collate as "C".) This string should
be enclosed in parentheses.
You can also represent characters by their corresponding octal, decimal, or hexadecimal values using the radix operators: %O, %D, %X. You must observe the following rules when defining your collating sequence:
The following string defines a collating sequence in which the double character LL collates as a single character between L and M. ("A"-"L","LL","M"-"Z")
|
Note
Exercise caution when using the multinational collating sequence to sort or merge files for further processing. Sequence-checking procedures in most programming languages compare numeric characters. Normal sequence checking does not work because the multinational sequence is based on actual graphic characters, not the codes representing those characters.
The following examples demonstrate the creation of user-defined collating sequences for use in specification files. See Section 11.8 for information about specification files.
/COLLATING_SEQUENCE=(SEQUENCE=ASCII,IGNORE=("-"," "))
252-3412
252 3412
2523412
/COLLATING_SEQUENCE=(SEQUENCE=("A"-"L","LL","M"-"R","RR","S"-"Z"))
Batch jobs are programs or DCL command procedures that run
independently of your current session. If you are sorting large files,
consider submitting the Sort operation as a batch job because the sort
will require some time. See Chapter 18, Chapter 15 and
Chapter 16 for more information about batch jobs and command
procedures.
11.5.1 Command Procedures
Specify the SORT command in your command procedure just as you would write it on the screen. If your default directory does not contain the files to be sorted, explicitly set your default directory in the command procedure or include the directory in the command file specifications.
Example
The following example submits the DCL command procedure SORTJOB.COM as a batch job. The text of the command procedure is shown following the command line:
$ SUBMIT SORTJOB
! SORTJOB.COM ! $ SET DEFAULT [USER.PER] ! Set default to location of input files $ SORT/KEY=(POSITION:10,SIZE:15) EMPLOYEE.LST BYNAME.LST $ TYPE BYNAME.LST $ EXIT
You can include the input records in the batch job by placing them after the SORT command with one record per line. Individual sort records can be longer than one line.
As with terminal input of records, specify the input file parameter as SYS$INPUT. Use the /FORMAT qualifier to specify the record size in bytes and the approximate file size in blocks. Approximately six 80-character lines equal one block.
The following example demonstrates including input records in a command procedure:
$ SUBMIT SORTJOB
! SORTJOB.COM ! $ SET DEFAULT [USER.PER] $ SORT/KEY=(POSITION:10,SIZE:15) - SYS$INPUT- /FORMAT=(RECORD_SIZE:24,FILE_SIZE:10) - BYNAME.LST $ DECK BST 7828 MCMAHON JANE ADM 7933 ROSENBERG HARRY COM 8102 KNIGHT MARTHA ANS 8042 BENTLEY PETER BIO 7951 LOWELL FRANK $ EOD
The following sections describe how to merge files.
11.6.1 MERGE Command
The MERGE command combines up to 10 (the high-performance Sort/Merge utility supports up to 12) sorted files into one ordered output file. You can merge input files that have the same format and have been sorted by the same key fields.
By default, Merge checks the sequence of the records in the input files to be sure they are in order. Specify the /CHECK_SEQUENCE qualifier if you want Merge to check the order. If you specify this qualifier and a record is out of order (for example, if you have not sorted one of the input files), Merge reports the following error:
%SORT-W-BAD_ORDER, merge input is out of order
You can use the same qualifiers with the MERGE command as you use with the SORT command with two exceptions:
Example
In the following example, the files BYNAME1.LST and BYNAME2.LST have already been sorted by customer name in ascending order. The command shown merges them:
$ MERGE BYNAME1.LST,BYNAME2.LST BYNAME3.LST
The output file BYNAME3.LST contains all the records from both files, BYNAME1.LST and BYNAME2.LST, as shown in the following figure:
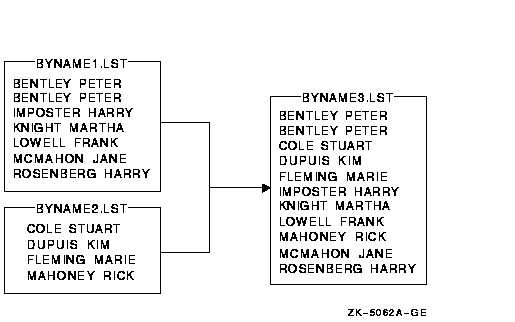
To merge files that are sorted using a specific key, you must specify the same key with the /KEY qualifier on the MERGE command line.
If you do not specify a key, Merge uses the default key described in Section 11.3.2.
Example
In the following example, the files BILLING1.LST and BILLING4.LST were sorted by account number (/KEY=POSITION:5,SIZE:4,DECIMAL). To merge the files into the output file MAILING.LST, enter the following command line:
$ MERGE/KEY=(POSITION:5,SIZE:4,DECIMAL) - _$ BILLING1.LST,BILLING4.LST MAILING.LST
The results of the merge are as follows:
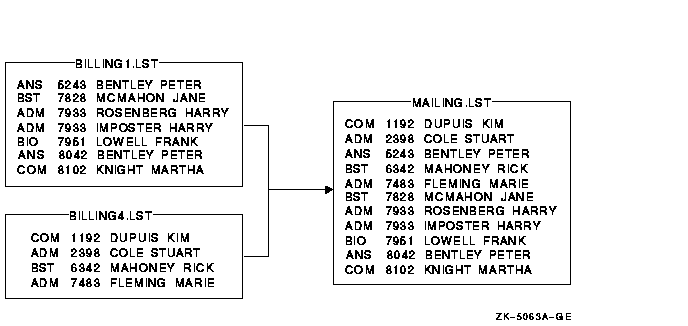
If you want to merge files that you know are in sorted order, you can
prevent sequence checking by specifying the /NOCHECK_SEQUENCE qualifier.
11.6.3 Identical Key Fields
As with a Sort operation, when input files contain records with
identical key fields, Merge does not necessarily maintain the same
order in which the records had appeared in the input file. To maintain
the input order of records with identical keys, specify the /STABLE
qualifier on the MERGE command line. To retain only one copy of records
with identical keys, specify the /NODUPLICATES qualifier.
11.7 Entering Records from a Terminal
Records that you want to sort or merge do not have to be in a file. You can enter the records directly from the terminal as you enter the SORT or MERGE command. The following table describes the procedure: Previous | Next | Contents